
Part 1 was about a small Class 2 model for a single app, where self-hosting rarely pays off. Here we turn it up a notch: a dedicated multi-GPU GLM-5.2 node for an entire dev team.
A quick example up front, before we take it apart below:
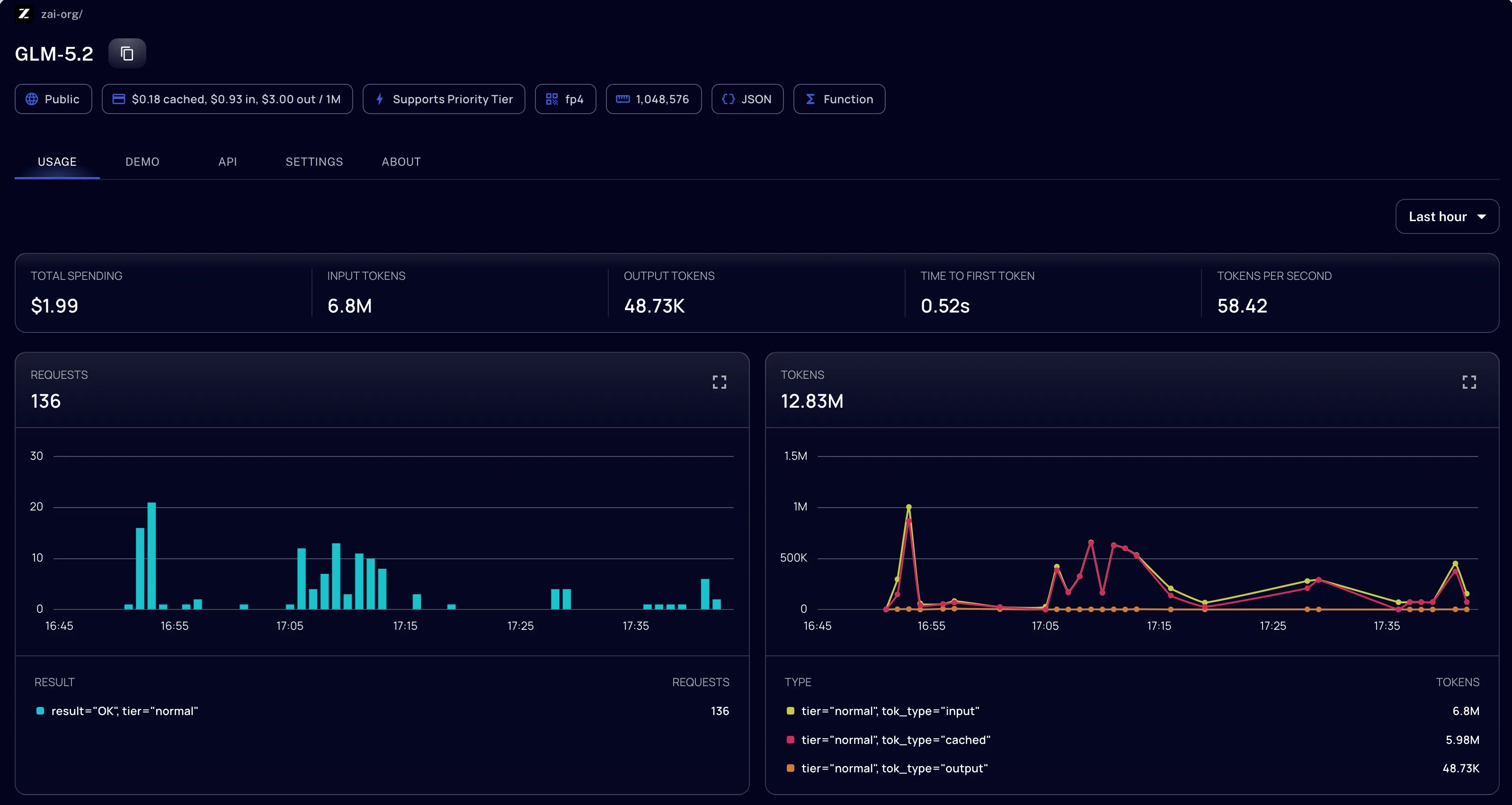
GLM-5.2 on the "medium" reasoning tier, used as an agent in OpenCode via a hosted API, implemented a complete FTP-integration feature ticket flawlessly, requiring real research up front rather than just frontend shuffling:
- Duration: roughly one hour
- Result: ~95 lines of production logic, ~55 lines of frontend/UI, ~160 lines of tests
- Cost per the usage dashboard: €1.85 (FP4 only!)
- Extrapolated to a single always-on agent (8 h/day, 20 working days/month): €1.85 × 8 × 20 ≈ €296/month
GLM-5.2 is a mid-range model (Class 3): big enough that it needs a full 8-GPU node, but small enough that it still fits on one node. That's exactly where it gets interesting. Anything a size above blows past a single node and forces specialized hardware (more on that at the end). The basics (who this is for, the four model classes, scope: inference only, OSS only) are covered in Part 1; here we dive straight into the numbers.
Our core thesis stays the same: self-hosting pays off in terms of sovereignty and independence. The pure costs are the interesting variable here.
1. GLM-5.2 for a dev team
GLM-5.2: example setup and cost breakdown for your own dev team.
Model basics: 743B total / ~39B active (MoE), 1M context
- FP8 weights: ~744 GB (+ KV + ~10–20% overhead)
- NVFP4/FP4 (4-bit): still ~372 GB
- Leanest option, if 4-bit is acceptable: ~4× H200 (564 GB) for the NVFP4 variant, with ~372 GB of weights plus plenty of KV.
- FP8 (recommended for quality/1M context): 8× H200 (a classic 8-GPU node, 1,128 GB VRAM). 8× H100 isn't enough; then it's 16× H100.
What does the minimal setup cost?
Even the lean variant (4× H200, NVFP4) costs, at an EU host like Nebius on the reserved tier (€2.28/GPU/h net), roughly 4 × €2.28/h ≈ €9.10/h net → in 24/7 continuous operation, ~€6,625/month. For development, even though NVFP4 has gotten better on the newer architectures, we'd rather run the model in full FP8 (better quality, cleaner 1M context). That simply costs double the cards: 8× H200 reserved ≈ €18.2/h net → ~€13,250/month in continuous operation (on-demand would run about €4.19/GPU/h, nearly double). After all, the developers' agents should get their work done quickly too :)

Performance for GLM-5.2 on this node (8× H200, FP8)
We run the model in full FP8 (1 byte/parameter): best quality, cleanest 1M context. What the eight cards deliver:
- Single user (batch 1): ~120–180 tokens/s per stream. The math: 8 cards deliver ~38.4 TB/s. Per token, ~160 GB is actually moved. That's not just the weights activated per token (~39B active, ~39 GB in FP8), but the effective memory throughput including KV-cache access and GLM-specific architecture overhead. 38,400 ÷ 160 = 240 × batch size.
- The KV cache: 8× H200 = 1,128 GB; after ~744 GB of FP8 weights, over 350 GB remain for the KV cache. That lets the system handle a large batch size (many parallel requests) before running into out-of-memory.
- Full load / system throughput: realistically ~12,000–18,000 output tokens/s system-wide (mixed context lengths), in FP8, which brings only a quantization loss versus the BF16 base model that's mostly negligible in inference (much less than more aggressive 4-bit formats).
If you're wondering why we're calculating with ~160 GB per token instead of the ~40 GB you'd expect from the MoE architecture: GLM-5.2 activates only ~39B of its 743B parameters per token; in FP8, that would work out to just ~39 GB that need to move per token, in theory. What's actually measured is significantly more, because KV-cache access and GLM-specific architecture overhead pile on top: effectively ~160 GB per token. For capacity planning, it's the measured number that counts, not the theoretical one, and that's actually good news: at this memory footprint, the system stays clearly memory-bandwidth-bound, so throughput depends almost entirely on available memory bandwidth, not GPU compute power, and therefore scales nearly linearly with more GPUs (more bandwidth = more tokens/s). Anyone calculating with the optimistic ~40 GB underestimates the bandwidth needed and ends up with less throughput than the planning promised.
How many developers does this make happy?
Depends entirely on how it's used. A human has a speed limit for absorbing information; a script doesn't. Capacity planning with a conservative average of ~15,000 tokens/s:
- Classic (IDE chat, boilerplate, explaining logs): ~100 tokens/s is enough for an "instant" reading feel; active time (actually waiting on generation) tops out at ~10%. → 15,000 ÷ 100 × 10 ≈ 1,500 developers. For standard dev workloads, this setup is wildly oversized: that's enough to serve an entire corporate IT department.
- Heavily agentic (autonomous agents, browser/E2E tests, refactoring loops across whole repos): ~300 tokens/s per agent, active time close to 100% (agents keep iterating without a human thinking-pause). → 15,000 ÷ 300 = 50 parallel high-speed streams. At 1–2 always-on agents per person, that makes 25–50 hardcore power users perfectly happy.
| Developer type | Main use | Desired tokens/s | Team size |
|---|---|---|---|
| Classic | IDE chat, boilerplate, explanations | 50–100 | ~1,500 |
| Agentic | autonomous agents, E2E/browser tests | 200–500 | 25–50 |
An 8× H200 cluster running GLM-5.2 in FP8 delivers high quality (FP8 costs only a mostly negligible quantization loss in inference compared to the BF16 base model) and single-handedly carries the agentic workload of an entire mid-size dev team (25–50 people) under full load, or an entire Copilot-style department in classic use. The scripts never have to wait on the GPU.
The full bill: what's added on top of the GPU rent
The ~€13,250/month above is just the GPU rent. Real production operation adds items that can be quantified with a realistic Senior DevOps/MLOps hourly rate of €75–150/h:
- Personnel & operating costs: by far the biggest hidden item. Self-hosting means someone has to handle infrastructure setup, monitoring, and incident response, including at night. For a running 8-GPU node that's realistically 20–40 h/month (capacity planning plus driver and model updates on top), at €75–150/h ~€1,500–6,000/month, even as a part-time share (0.15–0.25 FTE) alongside other work.
- Production layer (API gateway, K8s & co.): vLLM only provides a bare endpoint. Real usage needs a layer in front of it: authentication/API keys, rate limiting, load balancing across nodes, monitoring (Prometheus/Grafana), logging, possibly a queue, usually orchestrated via Kubernetes. Roughly 80–160 hours of one-off engineering time → €6,000–24,000, amortized over 12 months ~€500–2,000/month.
- High availability & redundancy: a single node is a single point of failure. A backup node doubles the hardware cost in the worst case: +€13,250/month for the FP8 setup. Alternative: a failover plan onto the API in case of an outage, instead of true redundancy, saves hardware but costs engineering time to build.
- Storage, network & model upkeep: weights need to be stored (fast volume for ~744 GB), models need to be kept current, and updates need testing, plus egress/network costs. Roughly €200–500/month, small compared to the other items but not zero.
| Item | Monthly (without redundancy) |
|---|---|
| GPU rent (8× H200, FP8, reserved) | €13,250 |
| Personnel (DevOps/MLOps, 20–40 h) | €1,500–6,000 |
| Production layer (amortized) | €500–2,000 |
| Storage/network/upkeep | €200–500 |
| Realistic TCO / month | ~€15,450–21,750 |
| + optional redundancy | +€13,250 → ~€28,700–35,000 |
Relative to the 25–50 agentic power users from above, that's ~€310–870 per developer per month (without redundancy), noticeably more than the pure GPU math (€13,250 ÷ 50 ≈ €265) suggests.
This calculation excludes any kind of "it's-there-anyway" costs: the assumption that an already-existing DevOps team, spare Kubernetes capacity, or unused rack slots would just absorb the operation on the side. That exact assumption is the self-deception that many internal TCO calculations end up failing on later. Capacity that's "there anyway" is rarely actually free; it's just missing somewhere else. The numbers above are therefore an honest floor for dedicated, planned-for effort, not a lowball estimate. Everyone has to do their own math with their own circumstances in the end, without fooling themselves with numbers that look too good.
What do you even compare this to?
We deliberately skip a direct comparison with the well-known subscriptions: Claude Opus with Claude Code, or OpenAI's Codex with GPT, don't compare meaningfully against a self-hosted GLM-5.2: different model class, different strengths, different tooling ecosystem entirely. The setups are too different to compare directly.
If anything, you'd compare GLM-5.2 to a model in the same league, something like a Kimi. Which one performs better in your own workflow, we leave up to you: everyone has their own experience there, and it shifts with every release anyway.
The verdict: when does it pay off?
For small teams, a dedicated GLM-5.2 node is simply too expensive. Even the lean 4× H200 setup runs ~€6,625/month in GPU rent, the FP8 node with 8× H200 ~€13,250/month; the full TCO including personnel, production layer, and operations comes to ~€15,450–21,750/month, or ~€310–870 per developer per month at 25–50 power users. If you instead run the node on-demand only during working hours (8h × 5 days), you cut the price noticeably but take on more operational overhead (spinning up/down, scheduling, model loading). Below ~15–20 full-time power users, personnel and infrastructure costs spread across too few people, and the math stays unattractive. Only with a larger team working agentically around the clock, or when compliance/data-protection requirements rule out an API anyway, does it tip in favor of the dedicated node.
The counter-calculation shows just how far that can tip. If you scale the measured €1.85/h from the example in the introduction up to 25–50 power users (pessimistically the middle, 37.5 always-on agents, running 24/7 instead of just by the hour), that works out to an API-equivalent value of 37.5 × €1.85 × 24 × 30 ≈ €49,950/month (~€50,000). Against that stands the dedicated node's TCO of ~€15,450–21,750/month. With real utilization from meaningful agent work, the dedicated node is therefore 2 to 3 times cheaper than the API-equivalent value, not more expensive. The catch: this only holds if the agents are actually working on real tasks almost continuously; a node sitting idle at night and on weekends gives that advantage right back.
The ongoing costs of hosted APIs and flat-rate subscriptions keep changing, though, and acceptable offers are already no longer a given today. We're seeing subscriptions increasingly give way to pay-per-token models, and token consumption from newer, agentic models is rising fast. Costs of several hundred euros per head per month are no longer the exception there; the financial gap to a self-hosted cluster is shrinking. The gain in sovereignty and independence from someone else's limits comes on top of that.
2. When one node isn't enough anymore: interconnect, GB300 NVL72 & rack scaling
More users than a single node can handle is the easy case: more independent nodes plus a load balancer (replication), with costs scaling linearly with GPU rent (~€13,250/month per additional node). It only gets expensive and complex when it's not more users, but a single model instance, that no longer fits on one node:
When fast interconnect actually becomes mandatory
It only becomes a problem when a single model instance no longer fits on one node (models even bigger than GLM-5.2) or when a single request needs more compute, memory, or context than one node delivers, say 1M context at low latency, for research or experimentation. Then ONE model instance has to be spread across multiple nodes, and the GPUs have to synchronize with each other at every layer (tensor/expert parallelism). Over a normal network or PCIe, that falls apart. That's exactly why NVIDIA builds racks wired internally to behave like a single GPU.
The answer: a whole rack as one GPU (NVIDIA GB300 NVL72)
NVIDIA's solution is to wire the entire rack together as a single, giant GPU. The GB300 NVL72 packs 72 Blackwell Ultra GPUs (B300) (plus 36 Grace CPUs) into one rack, connected via an NVLink switch sitting in the middle of the rack. All 72 GPUs talk to each other at full NVLink bandwidth, not over Ethernet but over a switch fabric inside the rack itself. To the software, it looks like a single, gigantic GPU. That removes the interconnect bottleneck, and a single model instance that needs multiple nodes (models beyond GLM-5.2, or particularly heavy single requests) runs at full scale. This isn't 72 individually purchased cards; it's an integrated, factory-wired system.

Source: NVIDIA GB300 NVL72
The physical reality: ~120 kW in one cabinet
A rack like this draws ~120 kW continuously. For comparison: that's like putting 60 space heaters on their highest setting into a refrigerator and closing the door. Air can't cool that anymore: racks like this are liquid-cooled (direct-to-chip), with a cooling loop like a small industrial process.
What does a rack like this cost?
There's no official list price, and since it's an integrated system rather than 72 individual cards, we have to estimate. Rough ballpark per B300 GPU ~€37,000–46,500 → ~€2.8–3.3 million for the GPUs alone; with Grace CPUs, NVLink switches, networking, liquid cooling, and chassis, a GB300 NVL72 realistically lands at roughly ~€3.3–4.2 million to acquire (an estimate, not an official price).
On top of that, the running electricity, by pure math: 120 kW × 24h × 365 = ~1,050 MWh/year; at €0.20/kWh, that's ~€210,000/year for electricity alone (plus cooling, space, redundancy in the data center).
→ That's the scale at which "self-hosting" definitively stops being about saving money and becomes a strategic infrastructure decision.
For the basics (target audience, the four model classes, scope) and a provider overview (where to rent GPUs, hyperscalers and EU neoclouds, with pricing), see Part 1.